오늘은 강이의 자바강좌에서 여러분과 약속한데로 자바 컬렉션 프레임워크에 대해 특강 형식으로 강의를 진행하려한다. 세계최초(?)로 공개되는 본 강좌를 들으면서 자바의 컬렉션에 대한 여러분의 궁금증들을 해소하고 그에 관한 폭넓은 사고와 이해를 통해 여러분의 지식을 한층 드높이는 계기가 되리라 단언한다. 특강이니만큼 자바소스나 프로그램은 제외할 것이고 읽는 도중에 아직 배우지 못한 내용들은 앞으로 진행될 강의에서 자세히 설명할 예정이니 그런게 있구나하고 편안하게 글을 읽어내려가기 바란다. 강이의 자바강좌에서 오늘 특강을 애독하는 이들은 아마 자바 컬렉션 프레임워크에 대한 전반적인 개요와 구조를 확실하게 이해하는데 큰 도움을 줄것이라 확신한다. 필자가 오늘 강의를 준비하기위해 도봉산과 관악산의 정기를 받으며 수개월동안 피와 땀이 맺힌 정신수양(?)을 한끝에 드디어 본 특강을 세상에 내놓으니 졸지말고 끝까지 함께해 주기를 희망하면서 본론으로 들어가보겠다.ㅎㅎ

자바 컬렉션 프레임워크(Java Collections Framework) 일명 JCF는 다수의 데이터와 객체지향적 시스템을 기반으로한 계층적 구조로서 여러 문제들을 풀기위해 서로 관련성이 있는 객체들을 통일하고 표준화된 설계들을 통해 유기적 관계들을 그룹화시키고 정형화시켜 보다 구체화된 다수의 데이터를 쉽게 처리할수 있는 방법을 제공하는 클래스들과 재사용할수 있는 컬렉션 데이터 구조들을 구현하는 인터페이스들의 집합을 말한다. 자바의 다형성을 이용해서 컬렉션 객체들의 메소드 형식과 형태를 동일하게 유지시켜 누구나 편하게 사용할수 있도록 일관성있게 제작된 자바 컬렉션 프레임워크는 자바2(JDK 1.2) 버젼에서 등장하여 많은 개발자들에게 자바 배열과 이와 관련된 여러 불편한 사항들과 단점들을 궁극적으로 보완할 최선의 대안책으로 제시되며 현재에 이르기까지 높은 성능과 뛰어난 상호운용성으로 크게 각광받고 있다. 거기다 기존의 1.4 버젼까지는 자료구조가 전부 Object를 넣어서 쓸수있도록 프레임워크가 설계되었으나 1.5인 자바5부터 제네릭을 지원하게 됨에따라 데이터형을 사전에 원하는데로 지정할수 있어 더욱더 편리한 사용이 가능해졌다.^^
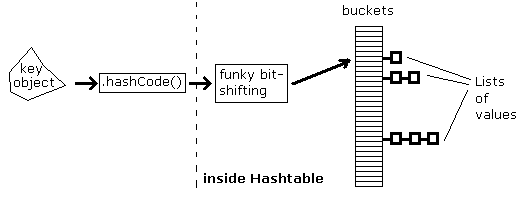
지금부터는 자바 컬렉션 프레임워크를 일반적으로 지칭하는 컬렉션이란 용어로 통일하여 사용하면서 이에 대해 심층분석해 보기로 하겠다. 컬렉션은 간단하게 말해 배열에 관련된 데이터를 다루는 인터페이스들과 이를 구현한 클래스들의 집합이라 할수 있을텐데 개발자 입장에서는 어떤 인터페이스들과 클래스들이 있는지 알아야할 것이고 이것이 어떻게 쓰이는지 기본이라도 알아야 써먹을수 있을 것이다. 따라서 이제부터는 여러분의 지루함도 달래줄겸 특별히 그림도 같이 보아가면서 공부해 보기로 하겠다.ㅎㅎ
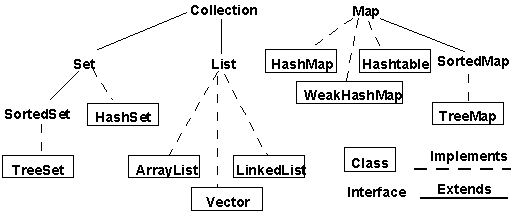
자바 컬렉션의 핵심 인터페이스들이다. 관련 클래스들은 어차피 인터페이스들을 알면 부수적으로 따라오는 것이므로 컬렉션에 대해서 논할려면 최소한 위의 계층구조 정도는 파악하고 있어야한다. 자바의 콜렉션 프레임워크는 크게 두개의 인터페이스(Collection과 Map)로 나뉘어진다. 보다시피 컬렉션의 뿌리인 Collection 인터페이스를 기반으로 이를 계승한 Set, List, Queue(자바5에서 등장)의 계층구조로 펼쳐지며 Collection 인터페이스를 계승하지 않고 독자적으로 존재하는 Map 인터페이스는 방식이 다르지만 성격은 같으므로 컬렉션에 속한다. 참고로 Map 인터페이스의 방식은 다른 컬렉션 인터페이스들과 다르게 키(Key)와 값(Value)을 이용 객체의 쌍(pair)으로 데이터를 짝지어 모아둔다. 여러분이 위의 인터페이스들만 다 이해하여도 자바 컬렉션 프레임워크의 대부분을 다 알고 있다고 해도 결코 과언이 아닐 것이니 다음 단락으로 가기전에 다시한번 위의 그림을 쳐다보고 아래로 이동하기 바란다.^^
컬렉션은 대부분이 객체를 어떻게 분류해 모아놓을지 다양한 연산을 수행하는 알고리즘으로 구성되어 있다고 볼수 있으며 구체적으로 표현해 보자면 컬렉션에서 원하는 객체를 찾는 Search 알고리즘과 객체를 특정한 순서대로 정렬하는 Sort 알고리즘을 중심으로 그 내용이 구성되어 있다고 간략하게 말할수 있겠다.ㅎㅎ
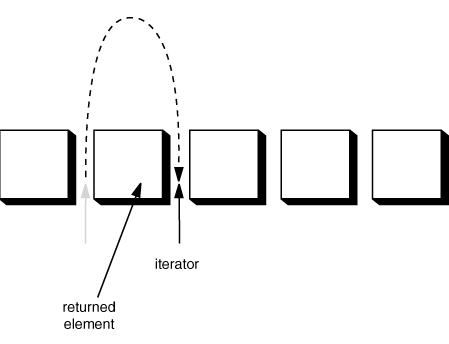
그럼 이제 각 컬렉션들에 대한 내용들을 요점정리해 보는 시간을 가져보겠다. 일단 컬렉션에서 맨상위 뿌리가 되는 Collection 인터페이스는 이를 계승하는 하위 인터페이스들에게 다음과 같은 메소드들을 지원한다.
boolean
add(E e)
boolean
addAll(Collection<? extends E> c)
void
clear( )
boolean
contains(Object o)
boolean
containsAll(Collection<?> c)
boolean
equals(Object o)
int
hashCode( )
boolean
isEmpty( )
Iterator<E>
iterator( )
boolean
remove(Object o)
boolean
removeAll(Collection<?> c)
boolean
retainAll(Collection<?> c)
int
size( )
Object[ ]
toArray( )
<T> T[ ]
toArray(T[ ] a)
외우라고 쓴것은 아니니 그냥 자연스럽게 눈이 가는데로 놓아두기 바란다.^^ 어차피 관련 클래스들을 공부하면서 자연스럽게 쓰게 되므로 저절로 알게 된다. 더군다나 여러분은 벌써 컬렉션 List에 해당하는 Vector와 ArrayList 클래스에서 벌써 일부 메소드들을 써보았을 것이므로 설령 생소한 메소드가 보여도 비슷한 맥락이므로 그다지 어렵진 없을 것이다.ㅎㅎ 그럼 컬렉션을 구성하고 있는 하위 인터페이스들의 특징과 그와 관련된 대표적인 클래스들을 함께 살펴보기로 하자.^^ 필자가 식음(食飮)을 전폐(全廢)하며 여러분이 한방(?)에 이해할수 있도록 최대한 핵심만 간추려 보았다.ㅎㅎ
- 자바 컬렉션 프레임워크 Java Collections Framework 구성요소들 -
Set: 요소들의 중복을 허용하지 않고 순서를 가지지 않는 요소들의 집합
Set 인터페이스를 구현해 가장 많이 쓰이는 대표적인 클래스:
HashSet
SortedSet: 요소들을 순서대로 꺼내 읽을수 있고 요소들이 증가되는 순서를 가지는 집합
SortedSet 인터페이스를 구현해 가장 많이 쓰이는 대표적인 클래스:
TreeSet
List: 요소들의 중복을 허용하고 인덱스를 이용해 순서를 가지는 요소들의 집합으로 시퀀스(sequence)라고도 표현한다.
List 인터페이스를 구현해 가장 많이 쓰이는 대표적인 클래스:
ArrayList
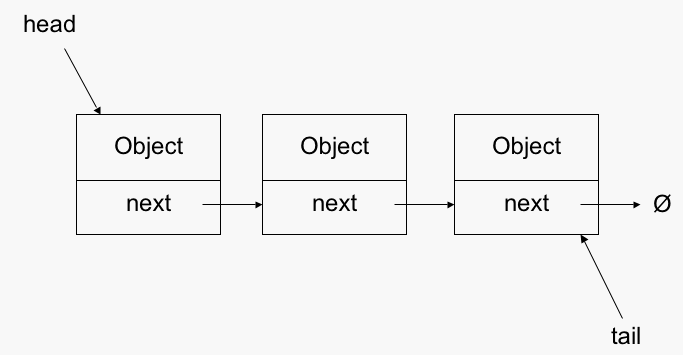
Queue: FIFO(First-In-First-Out)의 형태로 첫번째로 넣은 요소가 첫번째로 나오는 방식
Queue 인터페이스를 구현해 가장 많이 쓰이는 대표적인 클래스:
LinkedList
Map: 키(Key)와 값(Value)이 쌍(pair)으로 즉 두개의 객체로 이루어져 있으며 키는 중복을 허용하지 않고 값은 중복을 허용하는 순서를 가지지 않는 요소들의 집합
Map 인터페이스를 구현해 가장 많이 쓰이는 대표적인 클래스:
HashMap
SortedMap: 키에 해당하는 객체가 증가되는 순서대로 나열한 요소들의 집합
SortedMap 인터페이스를 구현해 가장 많이 쓰이는 대표적인 클래스:
TreeMap
간략하게나마 자바의 컬렉션 프레임워크를 구성하고 있는 핵심 인터페이스들의 특징들을 살펴보았다. 어차피 처음보는 것이라면 이해하지 못해도 전혀 상관없다. 관련 강좌들을 차례차례로 듣다보면 퍼즐 맞추듯이 하나하나 깨닫게 될것이다. 조각이 어느정도 맞춰진 후에 본 특강을 다시 읽는다면 머리속이 깨끗하게 정리가 될것이니 오늘은 부담없이 가볍게 넘어가기 바란다. 위의 인터페이스들과 이를 구현한 클래스들의 연관관계를 아래 그림들을 통해 순차적으로 감상하기 바란다.^^
그림들을 순차적으로 보다보면 자바 컬렉션 프레임워크가 어떤 인터페이스들과 어떤 클래스들로 구성되어 있는지 눈에 들어오기 시작할 것이다. 마지막 그림은 자바4와 자바5 버젼에서 어떤 것들이 컬렉션에 추가되었는지 살펴보라고 올린 그림이다. 물론 이것 이외에도 더많은 인터페이스와 클래스가 컬렉션에 관계되어 있다. 그중에서도 자주 쓰이는 것들만 모아놓은 것이라 믿도록 하자.ㅎㅎ 그림으로 다 때운다고 필자를 원망하지 말아라. 때론 그림들로 커버가 가능할때가 있는데 바로 지금이 그런 경우라 하겠다.ㅎㅎ
예상보다 특강이 길어졌는데 그동안 List에 속해있는 Vector와 ArrayList를 접하면서 컬렉션에 대해 누적되어왔던 여러분의 궁금증들이 이번 특강을 통해 많이 해소되었길 바란다. 앞으로 펼쳐질 강의들은 컬렉션에 관계된 중요 클래스들을 하나하나 접하면서 여러분들의 프로그래밍 실력을 한단계 드높여줄 컬렉션의 세계로 안내할 것이다. 여러분의 끊임없는 성원을 기대하면서 오늘 특강은 여기서 마치도록 하겠다.^^