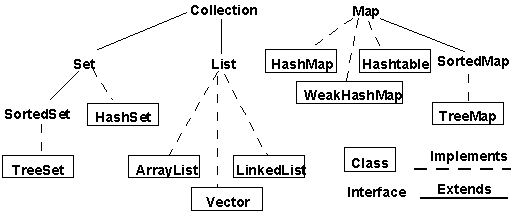
자바의 벡터 Vector 클래스에 대해서 공부해 보기로 할텐데 위의 그림들은 오늘 배울 자바의 벡터에 관련된 계보도이다. 자바의 벡터는 JDK 1.2 버젼부터 자바 컬렉션 프레임워크의 List를 구현한 멤버로서 재해석되었다. 컬렉션에 대해서는 차후에 설명할테니 궁금하더라도 지금은 넘어가기 바란다.ㅎㅎ 보는바와 같이 자바의 벡터 클래스는 java.util 팩키지에 들어있으므로 클래스를 만들기에 앞서 import java.util.Vector; 라고 먼저 관련 패키지를 불러들인후에 사용할 것임을 예측할수 있을 것이다. 예측하면서 본 이가 있으려나? ㅎㅎ 물론 클래스안에서 java.util.Vector를 직접적으로 불러서 쓸수도 있으나 보기 지저분하니 필자같이 청결한 이는 보통 쓰지 않는다.ㅎㅎ 더불어 Vector 클래스안에 어떤 메소드들이 있는지 눈요기좀 하라고 한것이고 다른 클래스들도 앞으로 하나둘씩 다루게 될것이라 미리 구경하라고 올려놓았는데 이런 필자의 뜨끈뜨끈한 배려심에 뭉클한 뭔가(?)가 전해졌길 바라면서 본론으로 들어가겠다.^^
자바의 배열을 공부하고 나서 슬슬 눈에 띄기 시작하는 것이 바로 Vector라는 녀석일 것이다. 비단 이 녀석뿐 아니라 배열의 형태가 워낙 쓰이는 곳이 많으므로 배열에서 확장된 개념의 클래스들이 상당히 많은데 오늘은 그중에서도 배열의 길이와 데이터형을 자유자재로 주무를수 있는 벡터에 대해서 공부해 보겠다.^^ 시작하기전에 워밍업을 하자면 강이의 자바강좌에서 벡터를 처음보는 접하는 이도 있겠지만 그렇지 않고 벡터에 대해서 잘 모르는 태반은 아마도 너무 복잡해 보여서 아니면 이것저것봐도 이해가 잘 안되어서 망설이다 여기까지온 이들이 많을 것이다. 그렇다면 모두 환영한다. 벡터에 지친 자들아, 모두 내게로 오라~ㅎㅎ
오늘 잠시만 이 강의에 집중하면 여러분은 자바의 벡터에 대해서 상당한 자신감으로 무장하게 될것이라 단언한다. 더군다나 이번 강의는 다른걸 공부하라고 강요하지도 않겠다. 그냥 딱 한가지만 하면된다. 예제 딱 하나~ 이것만 공부하면 벡터에 대해서 어느정도 감을 잡게 될것이라 확신한다. 모든 것이 단 하나의 예제로 시작해서 예제로 끝나도록 필자가 이 예제 한편에 벡터의 초초초오 엑기쓰만 쎄리 퍼부었다는 점을 강력히 밝힌다. 따라서 다른건 몰라도 오늘 보여줄 이 예제에 대해서만큼은 필사적으로 타이핑(?)하고 가능하면 프린트까지해서 같이 따라오기 바란다.ㅎㅎ 자 시간 10분 주겠다. 딴짓하지 말고 아래 예제를 클릭해서 빨리 타이핑하고 실행해보기 바란다.^^
3
10
3
강이의 JAVA강좌
5
4
5
3
start
10
end
강이의 자바강좌
end
10
start
middle
true
false
5
true
0
==========
예제를 실행하면 위와같이 결과값이 찍힐 것이다. 이제 본격적으로 예제분석에 들어가보기로 하겠다. import 부분은 관련 클래스 쓸려고 가져온 것이니 넘어가고 이제 메인메소드 안으로 들어가 보겠다. 일단 벡터를 사용하기 위해 벡터 클래스를 이용해서 객체생성을 하고 인스턴스 인자로 v를 만들었는데 괄호안에 (3,2)가 있다. 이게 무슨 뜻인가 하면 벡터의 길이를 3으로 하고 모자르면 길이를 2씩 증가시키라는 명령이다. 만약 괄호안에 아무것도 쓰지않고 벡터의 객체생성을 하였다면 기본적으로 길이는 10으로 할당된다. 그리고 모자르면 원래 기본길이의 두배씩 증가시킨다. 20 40 80 이런식으로 말이다. 따라서 어느정도 예측이 가능하다면 효율성을 고려해 제어시켜주는 것이 바람직하다. 옆에 주석을 달아놓은 것은 여러분이 이해하기 쉽도록 벡터가 어떻게 변해가는지 써놓은 것이니 조금이나마 벡터의 개념을 여러분이 이해하는데 도움이 되기를 간절히 희망한다.^^
다음 코드에서는 v.capacity( ) 즉 벡터의 용량메소드를 이용해서 프린트하라는 것인데 이 메소드가 하는 일이 벡터의 용량 즉 얼마만큼의 요소를 집어넣을수 있는지 길이를 알려주는 메소드다. 벡터의 메소드들이 무엇이 있고 무슨 일을 하는지는 자바 API를 찾아보면 다 나오니 귀찮더라도 한번씩 보면서 쫒아오기 바란다.ㅎㅎ 하여간 그래서 결과에 3 이라는 숫자가 처음으로 찍히는거다.
다음은 add 메소드를 쓰고 있다. 그럼 여러분은 바보가 아닌이상 강력한 자바삘(?)이 오고 있을 것이다. 뭔가를 집어넣는구나~ 그렇다. 예제에서는 start라는 문자를 집어넣고 있다. 그래서 주석에서 보는 것처럼 처음에 start라는 문자가 들어간거다. 자 여기서 여러분들이 놀라야하는 부분이 있다. 응?? 문자열을 넣는데 뭐 스트링을 이용해서 정의하거나 데이터형을 알려주는 과정도 없이 그냥 벡터에다가 넣어버렸다. 아 놀랍지 않은가? 그냥 놀랍다고 하자.ㅎㅎ 놀라움의 연속으로 다음 코드에 정수 10도 저렇게 그냥 넣어버릴수 있다. 캬하~ add( ) 메소드나 addElement( ) 메소드나 하는 일이 같은데 그 다음줄을 보면 add( ) 메소드가 더 뛰어나구나라는 것을 느낄수 있다. add( ) 메소드는 예제처럼 벡터의 인덱스를 지정하고 그곳에 원하는 요소를 집어넣을수가 있는데 예제에서는 인덱스 1에다가 ok라는 문자를 집어넣으라고 했으니 옆의 주석에서처럼 ok가 중간에 들어가게된다. 인덱스는 항상 0에서 시작하니까 말이다. 이거 너무 자세히 설명하니 진도 안나간다고 여기저기서 항의하는게 들려오는 것 같구만.ㅎㅎ
다음은 벡터의 get( ) 메소드를 이용해서 프린트하라는 것인데 이 메소드가 하는일은 말그대로 얻어서 가져오는 것이다. 괄호안의 2는 인덱스 2의 위치에 해당하는 요소를 가져오라는 것이다. 따라서 10이라는 숫자가 출력된다. 그 다음에 다시 벡터길이에 대한 용량을 찍으라고 하니 변한게 없으니까 아까처럼 3을 찍을 것이다. 그리고나서 강이의 JAVA강좌를 찍는다.ㅎㅎ 광고가 아니라 공부할때 따라가면서 결과값 보기 좋으라고 써넣은 것이니 필자를 탓하지 말아라.^^
자 이제 벡터의 새로운 마법(?)이 펼쳐진다. 20을 넣었는데 어라.. 다음 코드에서 벡터용량을 찍어보니 신기하게도 길이가 5로 증가하였다. 왜 벡터용량의 길이가 3에서 5가 되었을까? 기억이 안난다면 메인메소드의 첫째줄로 가보면 답이 있다. 객체생성을 할때 처음 길이용량을 3이라 놓고 모자르면 2씩 증가시키라고 하지 않았는가? 바로 그렇다. 벡터가 이미 꽉 차 있었으므로 20을 넣을때 우리가 설정해놓은 자동수치인 2를 증가시켜 총 길이용량 5가 되는 벡터를 자동으로 만든 것이다. 그리고 다음줄에 보면 size( ) 메소드를 이용해 프린트하라고 하였는데 4가 찍힌다. 여기서 size란 무엇을 뜻하는 것일까? 여기서 사이즈는 벡터에 있는 요소들의 갯수를 알려달라는 의미다. 지금 길이용량이 5인 벡터이나 안의 요소는 주석에서 보는 것처럼 하나가 모자란 4개의 요소들만 있다. 우리가 지금까지 4개의 요소들만 넣어왔으니까 말이다.^^
다음 코드는 벡터에 end를 넣은 것이고 그 다음줄을 보면 처음봐도 감이 올것이다. remove( ) 메소드를 썼으니 뭔가 없애라는 것일텐데 괄호안에 ok를 써놨다. 여기에서 벡터의 또다른 놀라운 힘을 느낄수 있다. 이렇게 인덱스를 이용하지 않고 요소를 직접적으로 지정해도 관련 요소를 벡터에서 없애버릴수 있으니 말이다. 이렇게 요소가 제거되면 주석에서 보는 것처럼 벡터 요소들이 알아서 저렇게 정렬된다. 다음줄은 인덱스로 관련 요소를 제거하는 방법이다. 2를 넣었으니 정렬된 벡터에서 다시 인덱스 2에 해당하는 위치의 요소인 20을 없애게 되고 또다시 벡터 요소들이 알아서 정렬된다. 자유자재로 정렬하는 벡터의 기능이 기막히지 않는가? 놀라는 척이라도 혀~ㅎㅎ
다음줄은 벡터 길이용량을 찍으라는건데 보다시피 벡터의 요소가 제거된다고 해서 벡터의 길이가 줄어드는게 아니라는걸 알수 있다. 그러니 당연히 5가 찍힌다. 그런데 이제 넣을것도 없는데 용량이 아까우니 벡터 길이용량을 줄여버리자는 생각이 불현듯 든다. 그때 유용하게 써먹을수 있는 메소드가 바로 trimToSize( ) 메소드다. 이 메소드를 사용하면 주석에서 보는 것처럼 벡터의 요소들에 맞게 알아서 길이를 맞춰준다. 지금은 요소가 3개 있으니까 알아서 맞춰준다면 길이용량이 3이라고 찍혀야 되는데 아니나 다를까 아래에 출력되는 것을 보니 3이 찍히므로 제대로 작동되고 있다는 것을 알수 있다. 잠깐~ 필자가 지금 너무 힘들다.. 물좀 먹고 올테니 1분간만 쉬자.ㅎㅎ
자 다시 예제로 와서 보면 Enumeration이 나온다. 아까 패키지 불러들일때 썼으니 이거 써먹을거라고 짐작하고 있었을텐데 사실 이 부분이 오늘 이해하기힘든 가장 심오(?)한 부분이겠지만 필자가 최대한 간략하게 설명해 보겠다. 자바의 JDK 1.2 다시 말해, 자바 2에서 많은 기능들이 추가되었는데 그중에 하나가 바로 Vector와 같은 컬렉션 클래스들(위의 계보도 그림 보면서 다른게 뭐가 있는지 찾아보기 바란다.^^)을 관리하는 컬렉션 프레임워크(Collections Framework)라는 것이다. 물론 벡터는 예전부터 있어왔었다. 이 컬렉션 프레임워크에서는 Collection 인터페이스를 상속받은 모든 컬렉션 클래스에서 Enumeration을 사용가능하게 해놓았다는 것이 요지라 할수 있겠다. Enumeration은 자바의 초창기 버젼 1.0부터 있어왔던 것인데 이걸 조금더 발전시켜서 객체요소를 제거할수 있는 기능까지 첨가한 Iterator 같은 인터페이스도 이때 나오게 된것이다. 지금 예제에서 Enumeration을 썼는데 새로 나온 Iterator를 쓰는것도 가능하니 그건 여러분이 한번 도전해보기 바란다. 예제 코드를 조금만 바꾸면 되니 그리 어렵지 않을 것이다. 번외편이 너무 길었던것 같으니 다시 예제로 돌아가자.ㅎㅎ
이 Enumeration이라는 인터페이스는 Collection 인터페이스로 구현한 클래스안에 저장되어 있는 객체들을 손쉽게 꺼낼수 있도록 해준다. 우리가 지금 공부하고 있는 벡터 클래스가 바로 컬렉션 인터페이스 자체를 직접적으로 구현한 클래스이므로 앞서 말한바와 같이 이렇게 손쉽게 사용이 가능하다.^^ 옆을 보면 벡터의 elements( ) 메소드를 인자 e에 집어넣으라고 하는데 이 메소드가 하는 일이 벡터 안에있는 요소들을 모두 가져오라는 것이다. 그리고 안에 무엇이 있는지 프린트하려고 while문을 돌리고 있는데 Enumeration에 있는 hasMoreElements( )와 nextElement( ) 메소드를 이용해서 안에 값이 있는지 확인하고 있으면 true, 없으면 false값을 돌려주며 있을 경우 요소들을 차례차례 찍으라는 구문이다. 벡터의 get(i) 메소드 같은걸 이용해 증감인자를 써서 루프를 돌릴수도 있겠지만 보는바와 같이 예제처럼 Enumeration을 활용하면 아주 쉽게 처리가 가능하니 이렇게도 쓸수 있다는 것을 알아두기 바란다.^^ 그래서 결과값을 보면 벡터 요소들인 start 10 end가 차례차례 찍힌다.
다음줄로 와서보면 잠시 광고 아니 공부하기 좋으라고 신경쓴 문구(?)가 나오고 방금 얘기한 벡터 get( ) 메소드를 이용해서 괄호안의 각 인덱스에 해당하는 요소들을 출력한다. 그래서 순서데로 end 10 start 가 찍히는 것이다.
다음줄에 보면 insertElementAt( )이라는 메소드를 썼는데 이 메소드는 말그대로 어떤 위치에 요소를 집어넣으라는 것이다. 괄호를 보면 middle이라는 요소와 숫자 2가 적혀있는데 인덱스 2에 해당하는 위치에다 본 요소를 집어넣으라는 뜻임을 알수 있을 것이다. 그리고 주석에서 보는 것처럼 벡터의 길이용량이 이번에 또 5로 늘어난다. 저번처럼 middle을 넣기전에 이미 벡터 용량이 꽉 차 있었으니까 말이다. 아까 언급했으니 두번 설명 안하겠다.^^
다음 코드를 보면 elementAt( ) 메소드를 이용하였는데 이건 어떤 위치의 요소를 가져오라는 것인데 예제에서는 인덱스 2에 해당하는 요소를 가져오라고 하였으니 middle을 가져오게 되는데 이걸 캐스팅해서 스트링 변수 s에다가 넣어주었다. 캐스팅은 데이터형을 변환할때 사용하는 방식인데 저렇게 앞에다가 바꾸고자 하는 데이터 타입명을 써주고 괄호로 감싸주면 된다. 여기서 의아해하는 이들이 있을지도 모르겠다. middle이 스트링이지 않느냐? 데이터형이 같은데 왜 캐스팅을 하냐고 말이다. 좋은 질문이다.ㅎㅎ 벡터는 요소들을 몽땅 Object 형태로 보관한다. 그래서 데이터형에 관계없이 저렇게 자유롭게 쓸수 있는 것이다. 허나 이걸 끄집어내서 쓰려면 요소값에 맞는 데이터형으로 다시 변환시켜줘야하므로 캐스팅을 이용한거다.^^ 그냥 벡터에 있는 메소드 이용해서 출력해도 되지만 이렇게 관련 변수로 넘겨받아 출력도 가능하다는 것을 보여주기 위해서 필자가 이처럼 어려운 길을 걷고 있는 것이다.ㅎㅎ 그래서 다음줄에 s를 출력하면 middle이 찍힌다.
이번에는 boolean이 나왔다. 참인지 거짓인지를 알아보자는건데 변수를 bool로 만들고 값을 넘겨받으려고 보니 벡터의 contains( ) 메소드라는 것이 보인다. 이 메소드가 하는 일은 요소값을 넣어주면 벡터에서 그 요소가 있는지를 찾고 있으면 true, 없으면 false값을 돌려준다. 예제에서는 end가 있는지를 찾으라고 했는데 있으므로 처음엔 true가 출력되고 다음에 20이 있는지를 찾으라고 해서 찾아보니 이번엔 없어서 false를 출력하는 부분이다. 이제 다 끝나간다. 힘내자.ㅎㅎ
다음 코드를 보니 removeAllElements( ) 메소드가 나온다. 이거야 하는일을 모르는 이가 없을거라 본다. 말그대로 모든 요소들을 제거하라는 것이니 주석에서처럼 텅텅 비게 된다. 그래서 다음줄에 벡터 길이용량을 체크하라고 했더니 5가 찍힌다. 요소들이 제거되어도 벡터 용량과는 상관없음을 알수 있고 이것 대신에 벡터의 clear( ) 메소드를 쓸수도 있다. 다음 코드도 뜻이 명확하다. 안에 비었냐? 당연히 안이 비었으니까 true값을 돌려준다. 다르게 설명하자면 isEmpty( ) 메소드는 사이즈가 0일 경우에만 true를 리턴하고 그 이외의 경우에는 false를 리턴한다. 여기서 사이즈란 아까 배웠다시피 객체요소들의 갯수를 의미하는 것이고 다음줄이 바로 그것을 물어보는 것인데 아까 요소들을 제거해서 벡터에 어떤 요소도 없으므로 size( ) 메소드 값은 0이 찍힌다. 벡터에서 size( ) 메소드는 벡터의 길이 사이즈를 물어보는 것이 아님을 알아두기 바란다.^^
이로써 오늘 벡터 강좌를 마치도록 하겠다. 해보니까 다 이해가 가는 자기자신에게 놀라고 있진 않은가? 만약 그렇다면 자기자신을 향해 박수 10번을 치며 자축하기 바란다. 이번달이 10월이니까 말이다.ㅎㅎ 무슨 헛소리를 하는지 모르겠다. 알아서 마무리 잘하고 필자는 급피곤한 관계로 박수칠때 물러가도록 하겠다.^^